- Published on
Large-Language Models and Information Retrieval
- Authors
- Name
- Michael Shi
- Follow me



Introduction
Since December, I have been invested in learning and playing with ChatGPT, an OpenAI platform to generate text with a Large-Language model(LLM). Based on what I've seen so far, these LLMs have a lot of potential to disrupt and generate industries.With this in mind, my first thought was the similarity between this UI platform and google in terms of its information retrieval ability from text. The major difference between the two is that ChatGPT only utilizes pre-trained data to generate answers. As a result, it cannot access information on the internet. But what if it could?
Web-Crawling
In order to give GPT-3 the ability to browse the internet, the first problem I had resolve was transferring most information on the web into readable text. For this problem, I stumbled on DiffBot an API to help parse text from different types of websites such as article, discussion board, and video sites. With this and the YouTube Transcripts API, I could now freely programmatically access most information on the web. The next problem I needed to solve was navigating the web and naturally I came across Google Custom Search, a customizable search console and API for browsing the internet. With these two functionalities in hand, I could now query and retrieve text information.
As a side note, I think developing this web crawling functionality was a good experience because with a few good google searches I was able to avoid difficult technical hurdles altogether. It's always a good thing to check for pre-existing solutions especially in software engineering where it is heavily emphasized to simplify problems. More on this here
Semantic Queries
I really do believe the intersection between search and Large-Language models will be an important breeding ground for revolutionary information technology. This may not be the greatest way to describe this technology, but I like to think of LLMs as a universal query language because they demonstrate the ability to extract contextual meaning from a huge set of information structures.
With this in mind, I set out to use ChatGPT to find use cases for improved search. The first one I thought about was using ChatGPT to generate additional descriptors based on the keywords of the query to be appended to the search. This was a simple first introduction to this. It turns out this idea relate a lot to "query language" and the use of search specifiers that everyone is aware of such as "site:website", but no one actually considers to use on a consistent basis. There is actually an interesting paper that uses this idea of search specifiers by appplying a MuZero Monte-Carlo tree search methodology to train an LLM to choose specifiers for a search query. Additionally, this inspired WebGPT, OpenAI's approach to finding reliable training data, as it is the first paper cited.
Intelligent information retrieval
Although I find this paper extremely promising, I believe solely using semantic queries to navigate the information space as incomplete. My reasoning is that it relies to much on the actual search engine to bridge the gap between the original query and the distinct exploration routes for the search via the generated results. What I propose is to allow the agent to read individual page results to contextualize the specific domain of the original query and use this extracted information to generate search queries or even individual links. The main downside of this approach is the sheer amount of compute and time require to perform these operations at scale. This might be possible for large companies such as Microsoft or Google that have tons and tons of structured web information that can be cached. As an individual, I have decided not to pursue this path for intelligent information retrieval.
A human-centered approach
Because of the time constraints, I think the best way to improve search at scale is to support people's own search procedure. This can be done very easily with the available technology by providing a summarization and search generation tool for web browsing. So, I just made a neat little chrome extension to automatically read random blocks from the first 3 search results summarize them, and generate additional search queries.
Here it is:
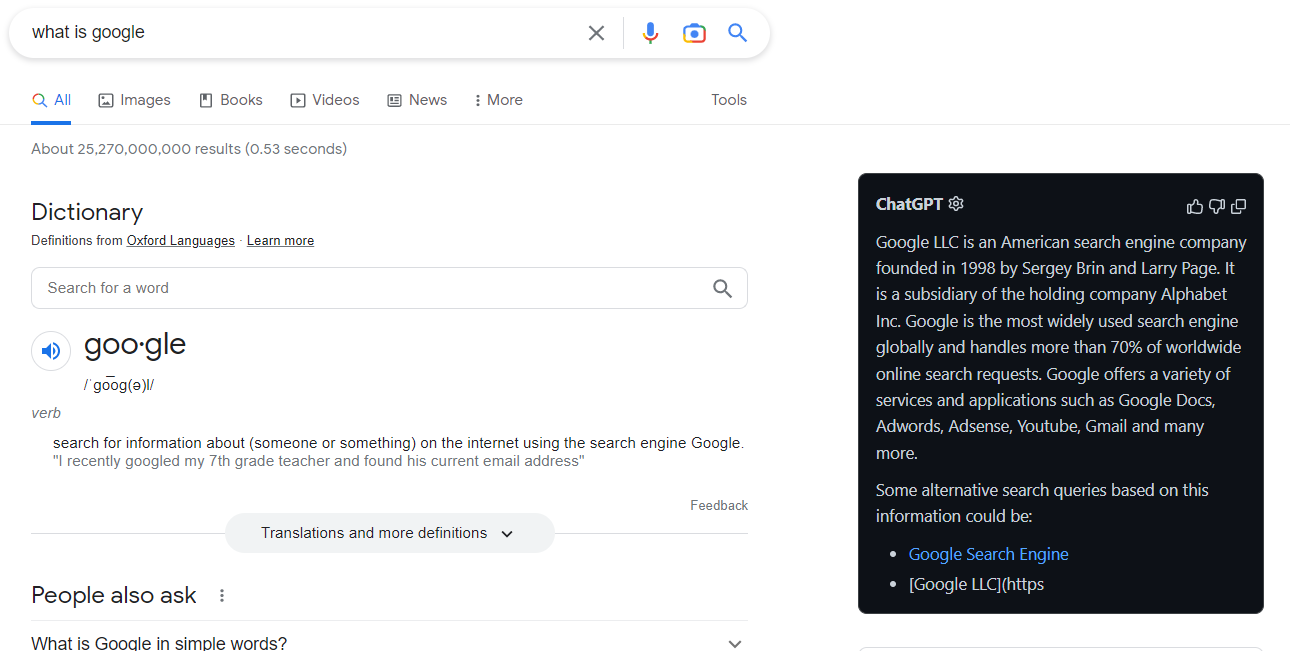
One downside to this approach is the fact I used randomness to index the passage. As a result, this leads to some unexpected or irrelevant information in the summary. However, I think using this idea of randomness is important for information retrieval. The whole point of this project was not to replace google as a search engine, but supplement the latent information gain from google to create a unique search path or rabbit hole for the user. This allows for the user to have fun and treat search as kind of a treasure hunt of interconnected links and queries. Personally, I feel I get the most out of search when I randomly stumble on some information that turns out to really shape my perspective on a topic.